Lecture 07 Hash Tables
之前的课时讨论了 Disk Manager 和 Buffer Pool Manager 下一个问题 是 Access Methods -- 访问方法层 -- 开始探讨如何构建负责执行这些查询的 执行引擎

访问方法是访问数据所采用的机制 -- 可以通过索引 表本身 甚至是其他潜在机制来实现
换句话说就是去找数据所采用的机制
先讲hash tables, which is an unordered structure. 然后探讨 树形数据结构 -- 提供键的排序功能
Hash Table
hash table本质上是一种关联数组 能够将键映射到值
我们使用一种 hash function 能够让我们本质上计算出数组内的某个偏移量 将任意键归约到我们可以跳转到哈希表中某个位置以找到我们正在寻找的那个事物的整数域
该哈希函数 必须 能够接受任何可能得键值 --- 需要考虑能够在数据库系统中可以定义的任何类型 以及系统本身内部可能存在的任何元数据 -- 通过映射 -- 归约为一个整数
Space Complexity: O(n)
Time Complexity: -Average: O(1) -Worst O(n) 必须处理 冲突
最坏的情况就是哈希表中的所有槽位 都已满 不得不进行循环
解决这个问题的一个好的方法 是将哈希表的大小设定为大约2n -- n为预期的键的数量 怎么知道数量? 后面会讲
a simple hash table
最简单的哈希表构建方式是 静态哈希表 -- 只需要malloc 生成一个巨大的数组 该数组为每个可能得键分配一个槽位 然后然后对键取模 找到偏移位置
在这个数组中 并不存储键 本质上只是一个指向其他位置的指针 -- 那个地方将包含键和值在一起
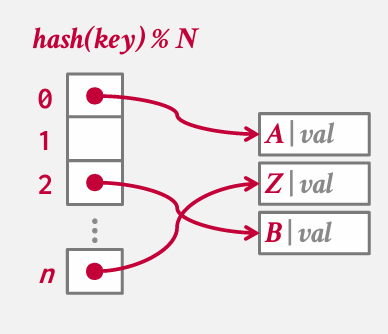
存储原始键的原因在于 由于可能发生冲突 有可能不是哈希函数算出来的位置 这里的val可能是一个指向tuple的指针 比如 record id 或者是一些其他的附加值
这种方法的问题:
静态 不处理冲突 键不一定唯一
完美哈希函数 保证无冲突 在现实世界是不存在的 我突然想起了 区块链的那个课讲到hash function的一些知识 比特币中的密码学基础
构建哈希表的时候 两个决策 考虑两个问题 或者说 hash的核心其实就是这两部分
- Design Decision 1: Hash Function
- Design Decision 2: Hashing Scheme
Today's Agenda
- Hash Functions: 当前的数据库用的hash function
- Static Hashing Schemes -- 经典的静态散列方案
- Dynamic Hashing Schemes -- 动态哈希方案
Hash Functions
哈希函数的基本思想是 拥有某个输入键 可以是任意类型 任意字节数的任意数值 -- 返回一个整数值 通常是64位,存在120位的哈希函数 但是好像数据库并不使用
We don't want to use a cryptographic hash function 比特币中的密码学基础 比如 sha256 -- 不会有加密手段 我们在构建哈希表进行连接操作的时候 无需担心数据泄露 因为系统外部的人员无法看到该数据结构
而且SHA-256算法相较于普通的Murmur Hash算法等 执行速度较为缓慢

一些系统如PostgreSQL 会自行编写哈希函数 但许多现代操作系统则倾向于采用现成的解决方案 -- 如 XXHash, MurmurHash SpookyHash
目前最先进的哈希算法是来自Facebook的XXHash 在XXHash3 中 该算法展现了最快的性能和最低的碰撞率
有一些系统采用CRC32或64进行整数哈希 因为x86架构中 实际上存在相应的CPU指令来执行这一操作
MurmurHash是不知名的网友编写的,拥有一个高效的 快速的通用哈希函数
Google采纳这一成果 通过分支开发出了City Hash算法 然后 又有了一个更新的版本叫做farm hash 具有更优的碰撞率
假设运行XXHash3 然后讨论一下hash table长什么样 如何处理碰撞
Static Hashing Schemes
Approach 1: Linear Probe Hashing
线性探测哈希法 -- 最常见 -- 专题七:查找 哈哈哈但在某些方面似乎缺乏智慧 但由于如此简单 实际上速度是最快的
Approach 2: Cuckoo Hashing
布谷鸟散列 -- 这是一个概念的变体 它基本上使用了多个散列函数
- Another Hashing Function in the Advanced DB course
- Pobin Hood Hashing
- Hopscotch Hashing
Swiss Tables
当前的研究表明 线性探测法 和 瑞士表(Swiss Table)是最快的算法 其他算法都比较花哨 他们试图提高性能 在插入数据时 通过移动元素来避免更常时间寻找键 但这些操作都会带来性能损耗 有时候在哈希处理中 采用朴素方法往往更为稳妥
线性探测具有多种变体 -- 比如可以采用二次探测 -- 不过先忽略这一点
Approach 1: Linear Probe Hashing
a gaint array of slots and we're going to hash into it.
如果想进进行插入操作 我们会进行哈希处理 -- 如果插槽空闲 -- 我们就插入正在查找的内容 -- 如果槽位被占用 我们只需要在下一个槽位 并在条件允许的情况下将其插入那里
如果循环回来 意识到我们回到了起始槽位 -- 意味着哈希已满 -- 终止操作 -- 扩容--翻倍
这项技术的实现状态之一 是 Google的Avacel项目 -- 一种扁平哈希映射类型或数据结构
这总方法有时候也被称作是开放寻址哈希 (open addressing hashing) -- 因为给定的键并不能保证它总是位于同一地址或是同一位置的槽中
在Python中获取一个字典 本质上也是获得了这么一个结构
process:
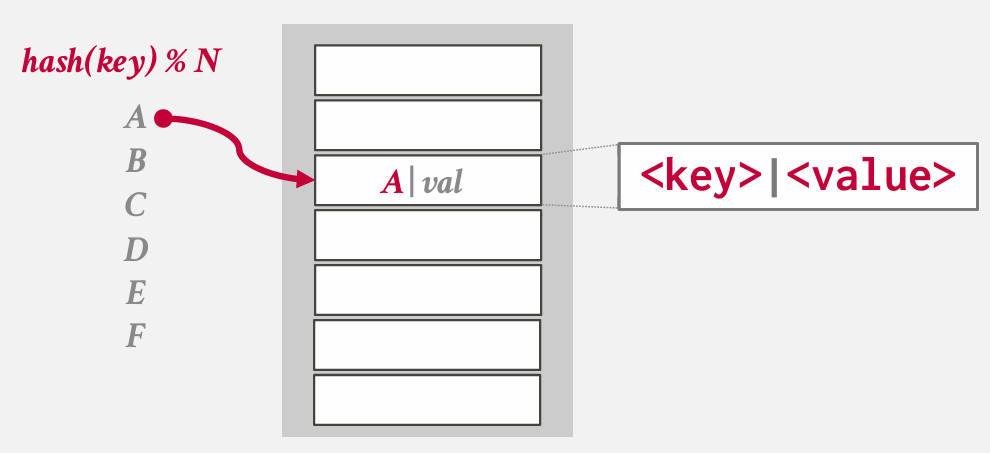
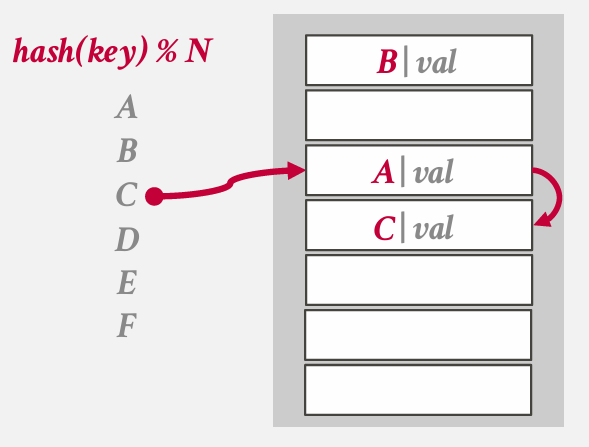
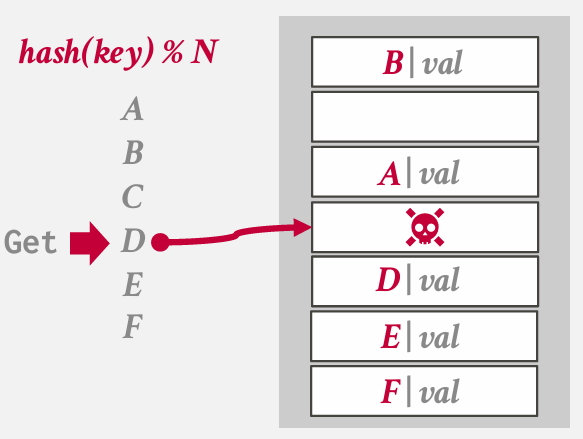
which problem?
deletion sucks -- lose the whole chain
solution 1: Movement
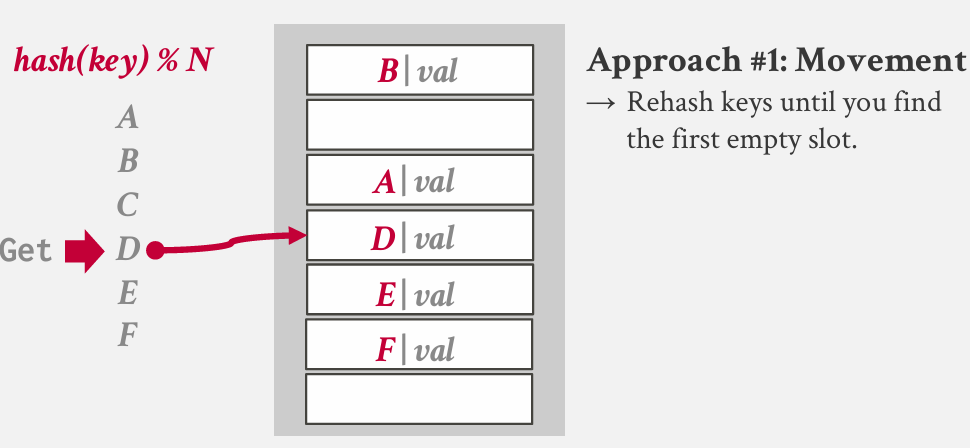
bad idea because of we must move all thing
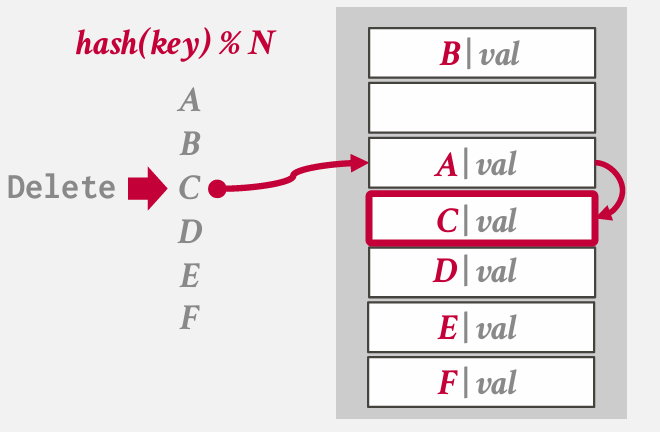
solution 2: Tombstone -- good idea -- a delete flag
这里的思路是 删除C 并非将其置为空 而是放置一个小标记 表明这个槽位曾经有一个主键已经被删除 会跳过 插入时 也可以放进去
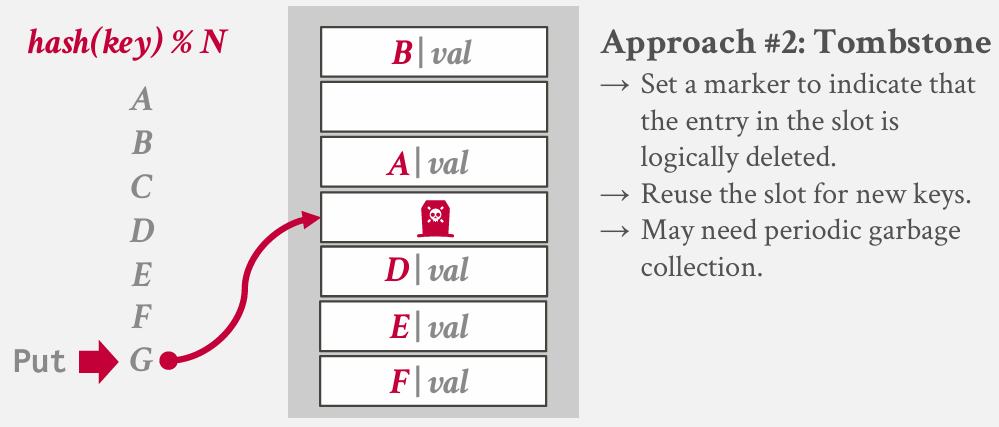
have a challange -- how represent tombstones -- how represent empty -- 如何表示我拥有一个null key(which you can do in a DBMS)
我们可以采用之前讨论过的技巧--在分槽页中操作--在哈希表的每个页面的头部设置一个位图bitmap 在页面的头部追踪
non-unique keys how to deal with
非唯一键 就是允许 key相同 value不相同的多条记录
Choice 1: Separate Linked List
不再存储键值 而是该值作为一个指针 like a page id 指向存储我的值链表的某个其他位置
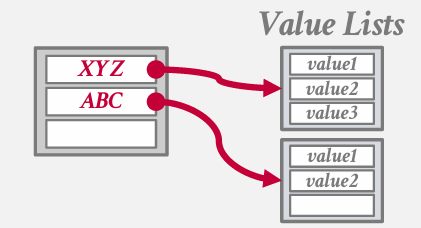
Choice 2: Redundant Keys
more common 将冗余键一起存储
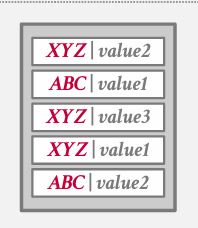
出于简化操作 大多数系统采用冗余键方法 而非维护非唯一键的独立链表和唯一键的内联版本 因为这样无需实现多种方案
optimization
你可能有不同的哈希表实现 -- 具有不同的机制 --比如何时分割 如何存储 -- 都基于存储结构
Specialized hash table implementations based on key type(s) and sizes 基于键类型和大小的专用哈希表实现
一个显而易见的想法是 如果我想要构建支持字符串键的哈希表 根据字符串长度 来设计不同哈希表的表现方式
- 如果我的字符串比较小 比如64位或更小 --- 直接在哈希表中存储
- 如果是一个很长的字符串 -- 我只想拥有一个指向实际字符串本身的指针
Store metadata separate in a separate array. →Packed bitmap tracks whether a slot is empty/tombstone
我们讨论了存储元数据的方式 like a tombstone, a null value, a empty slot -- store in page header -- so 我们拥有了一组紧凑排列的位 -- 实际上会将数据存储在一张完整的hash table中 Google Hash Map 采用了这种方式 他们为元数据设置了一个独立的 更为紧凑的小型哈希表
Use table + slot versioning metadata to quickly invalidate all entries in the hash table.
来自于Clickhouse -- 一家俄罗斯的公司
ClickHouse采用了一种版本控制的方法。表有一个全局的版本计数器,而每个槽可能有自己的版本号。当需要删除所有条目时,只需递增表的版本计数器,而不需要修改每个槽的状态。之后,在查找时,比较槽的版本号和表的版本号,如果槽的版本较低,则认为该条目已被删除。这样,不需要逐个处理槽,只需改变一个全局变量,从而快速无效所有条目。
那具体怎么实现呢?假设每个槽有一个版本号,初始时表的版本号和槽的版本号一致。当进行删除操作时,表的版本号递增。此时,所有现有的槽的版本号都低于新版本,因此在查找时会被视为无效。而当新的条目插入到槽中时,槽的版本号会被更新为当前表的版本号。这样,只有那些在版本递增之后插入的条目才是有效的,之前的所有条目都自动失效了。
这种方法的好处在于,删除操作的时间复杂度是O(1),而不是O(n),因为不需要遍历所有槽。同时,内存被重复使用,因为当槽被重新插入时,其版本号会被更新,旧数据自然被覆盖,无需重新分配内存。
Approach 2: Cuckoo Hashing
linear hash(线性哈希) 变体---> linear prep hashing(线性预哈希) cuckoo hashing(布谷鸟哈希)
这里的思路是 与其使用单一的哈希函数来查找哈希表中的一个位置 如果拥有多个哈希 对多个位置进行哈希处理 然后找到哪个位置有空槽
不用逐一扫描
这将确保所有的查找和删除 都是O(1) 因为无论多少个哈希函数 都不用扫描全局
采用Cuckoo Hashing的系统仅有一个 --IBM的OLAP加速器 named Blu
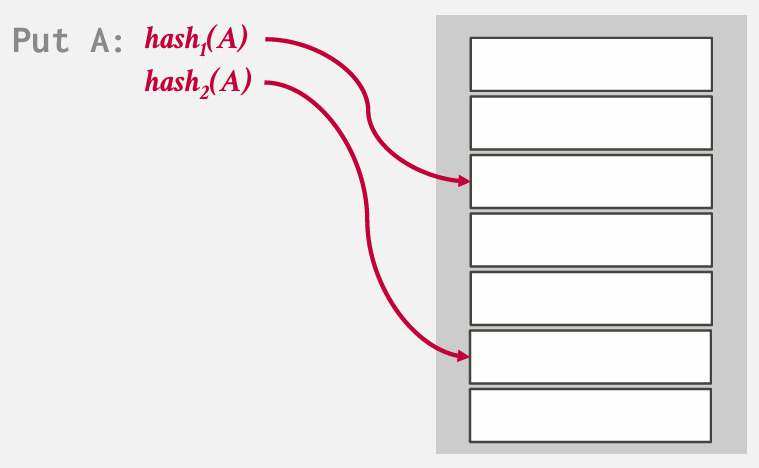
example 我们拥有一个单一的哈希表 但无论何时进行操作 都会使用两个哈希函数
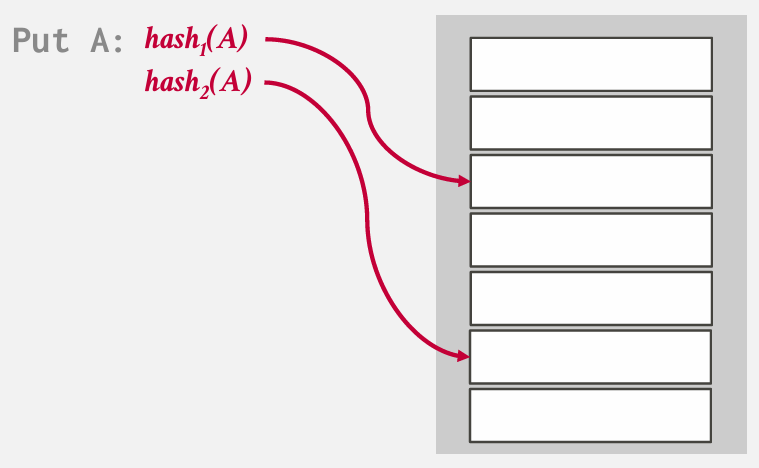
两个hash function 会产生两个位置 --- 可以采用概率选择一个位置 也可以直接选第一个
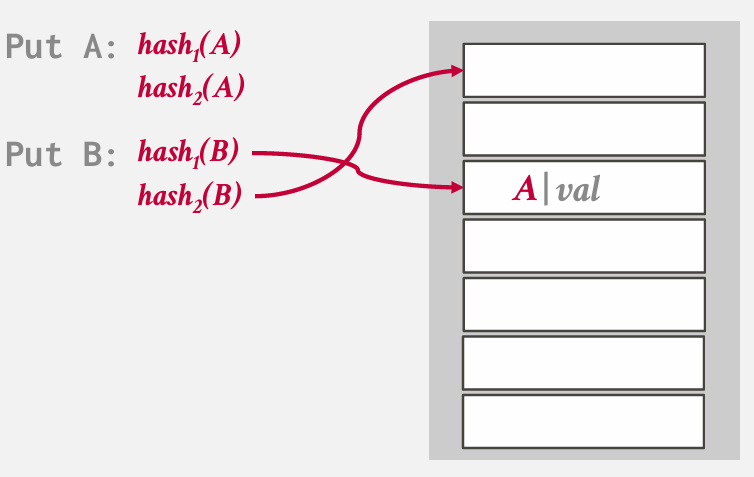
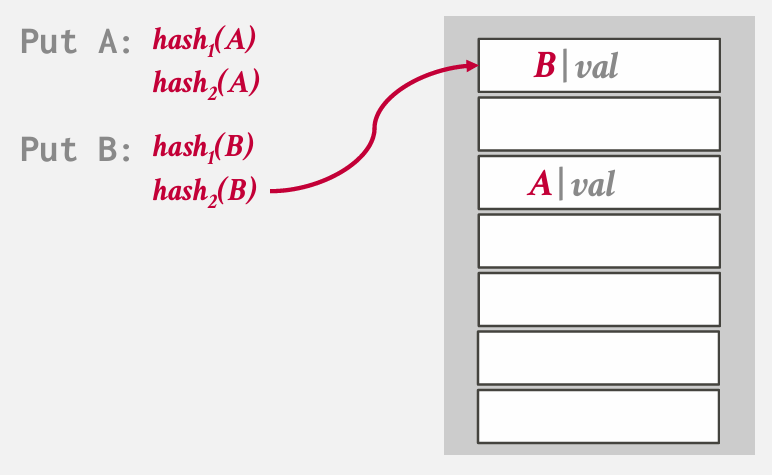
如果两个位置都被占用 就必须采用某种协议或方案 淘汰一个 be like
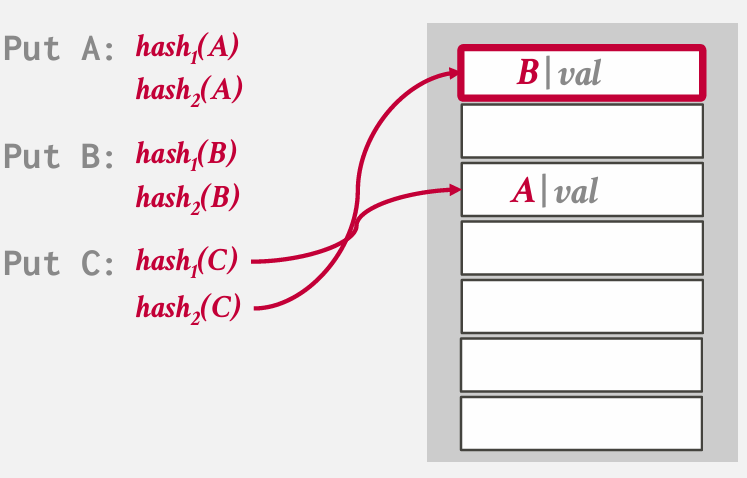
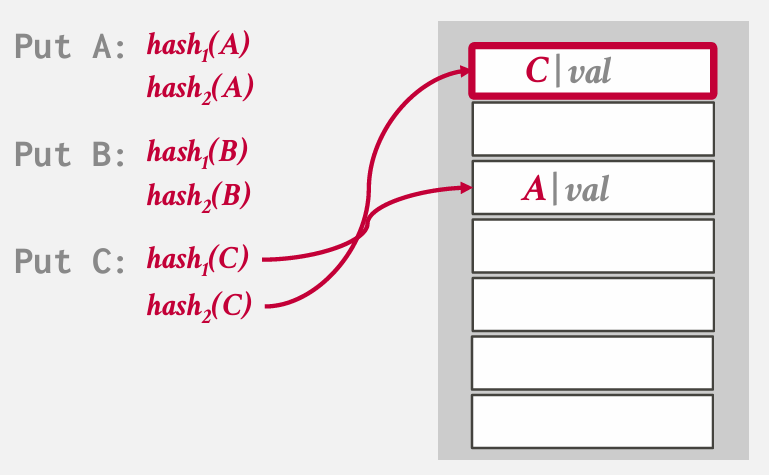
但我们又必须把B重新放回去
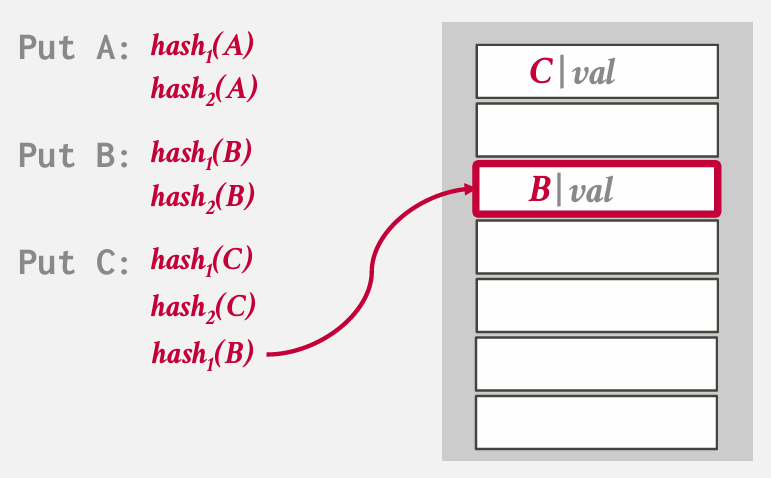
刚刚用的hash2 所以放到用hash1的地方
A又得放回去
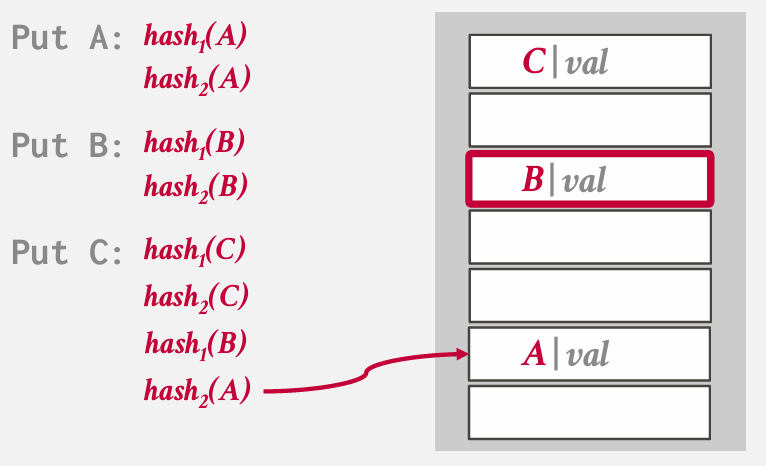
如果在尝试进行中 发生了环绕 -- 就需要扩容
如果要查找B 会对B进行两次hash 然后进行检查
Dynamic Hashing Schemes
动态哈希 以增量方式调整hash table大小 无需重建整个结构
- Chained Hashing
- Extendible Hashing
- Linear Hashing
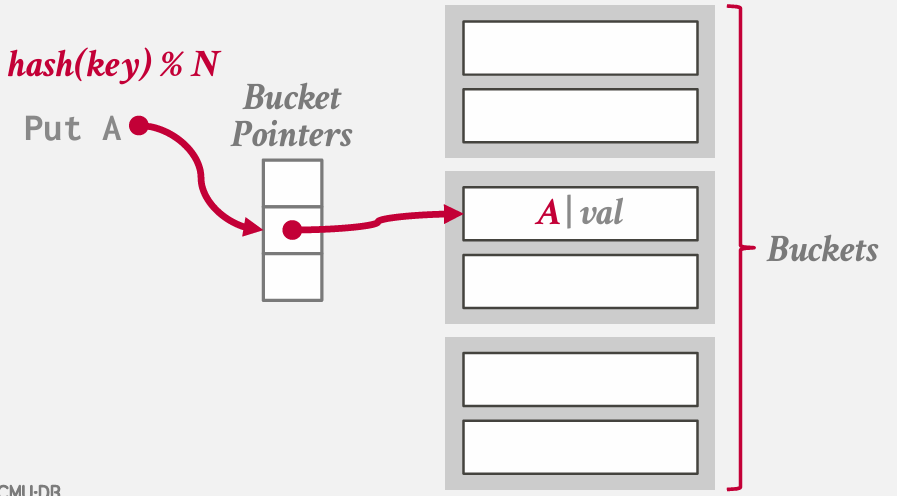
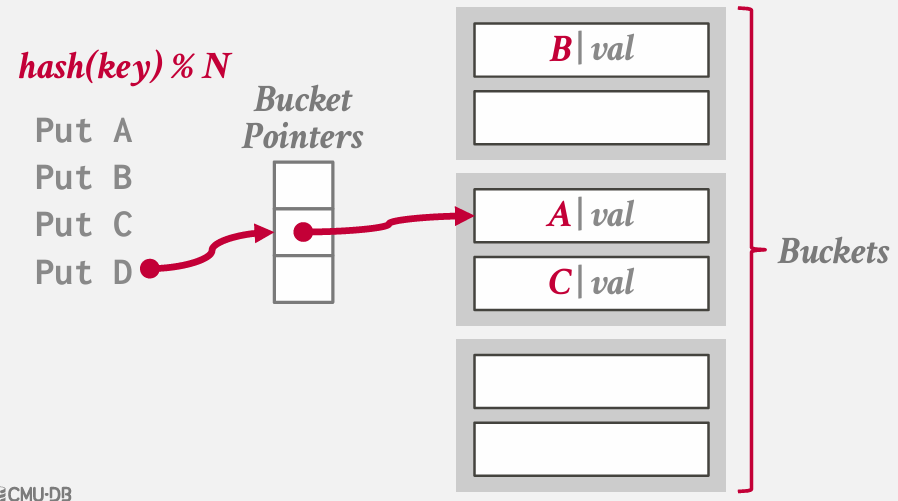
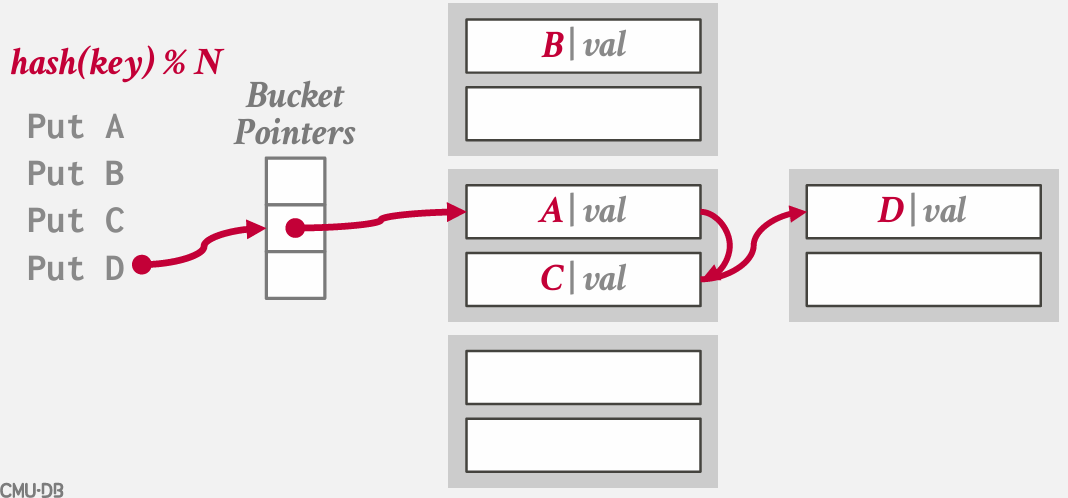
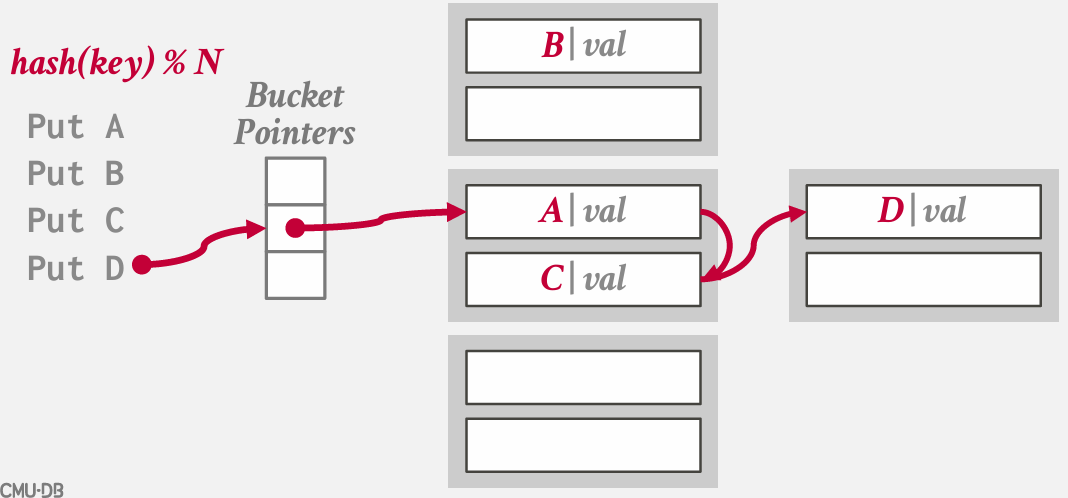
chained hashing
基本思想是不再需要一个包含所有槽位的大型数组来插入键值 -- 而是将数组简化为指向链表 链 或 桶的指针 -- 这些链表或链中包含了哈希表中对应槽位的所有键值
在Java中分配一个哈希映射时,本质上就是得到的这样的结构
在最坏的情况下 所有键都散列到一个槽中 最终基本上要进行顺序扫描
不过如果我的hash function --- 得到良好的分布
思考这个问题的方式 是 我们实质上 将之前拥有的巨大哈希表分割成了更小的哈希表
仍然可以使用tombstones
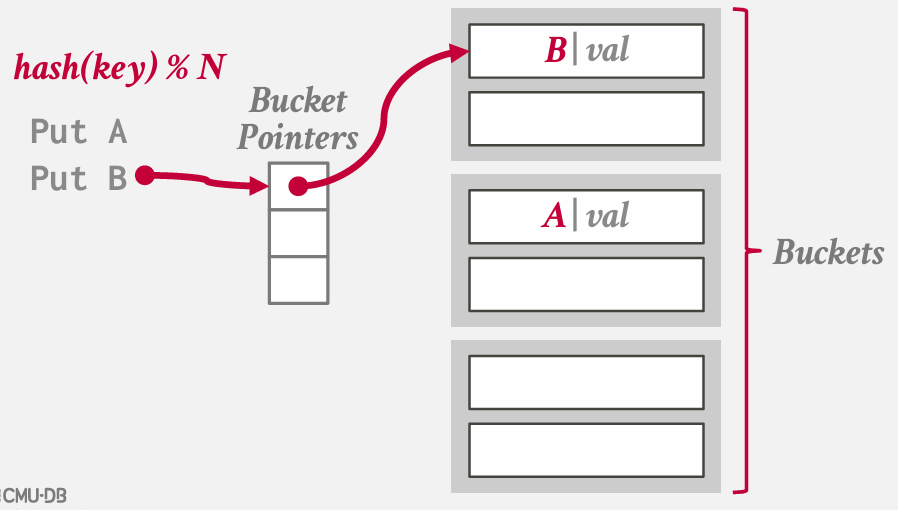
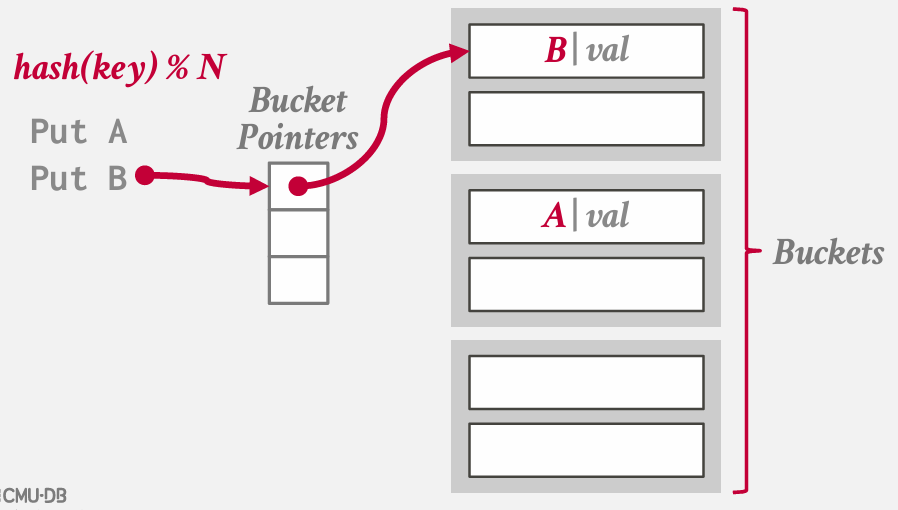
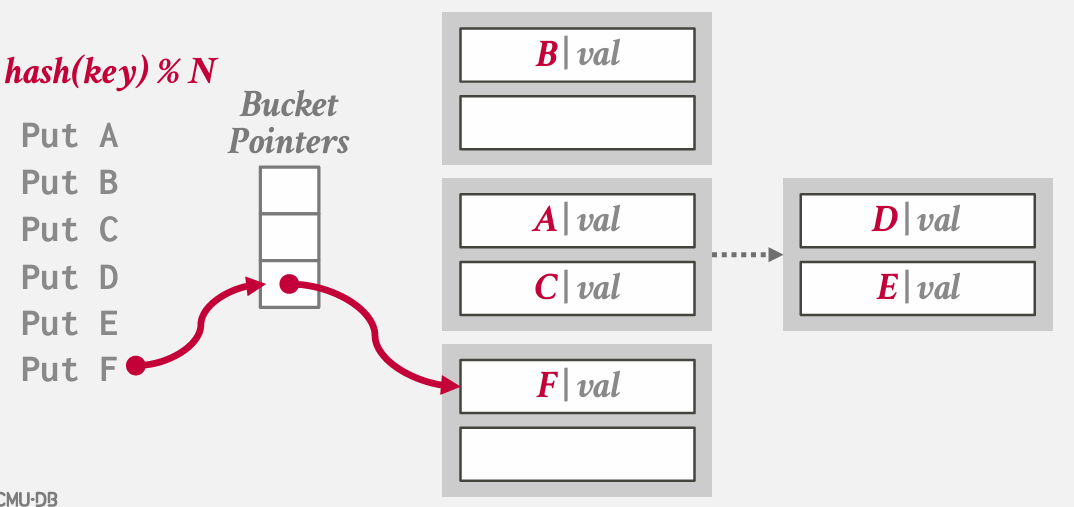
这种方法的好处在于 我们可以再一个桶内扩展键列表 而不影响到表的其他部分
但可以采用一种两级哈希表的结构 其中第一个哈希表会将你引导到bucket 桶内是一个个哈希表
a simple optimization --- use Bloom Filter(布隆过滤器) -- 告诉你某个键存是否存在于哪个bucket中
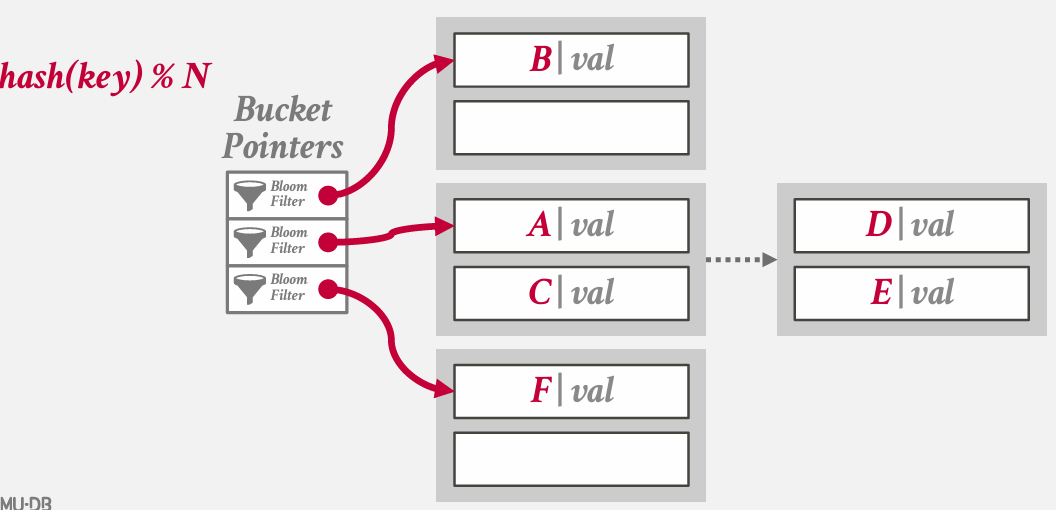
what is bloom filter
bloom filter是一种概率性数据结构 能够回答集合成员资格查询
filter和index不同 -- index会告诉你key在哪 -- filter只能表明 key 是否存在
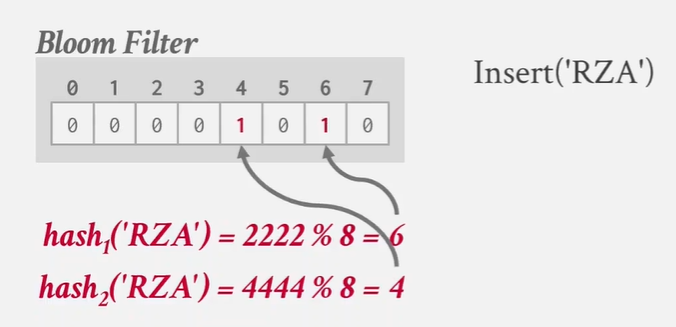
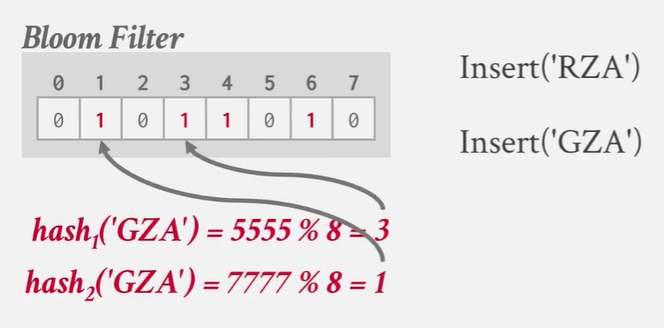
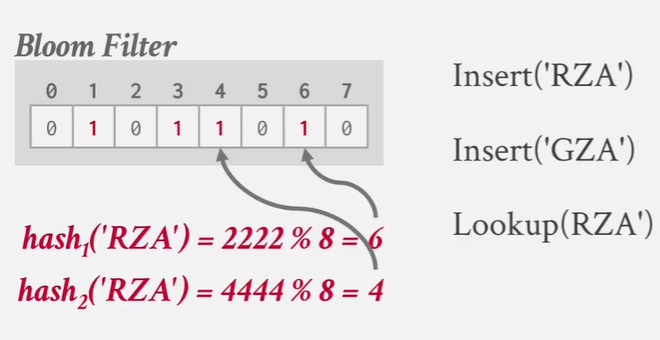
need both 1 -》 true
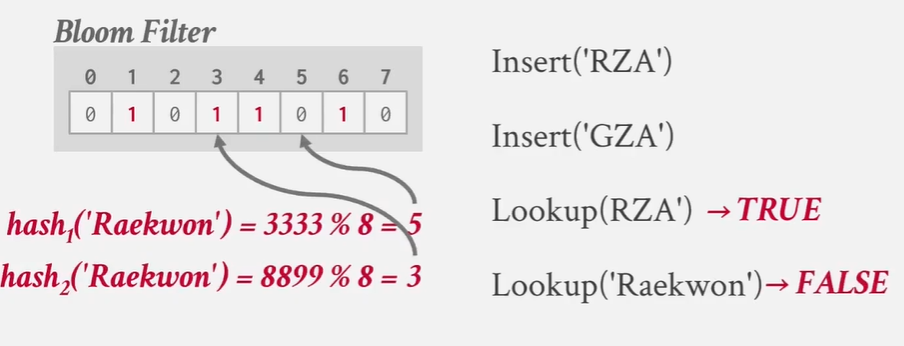
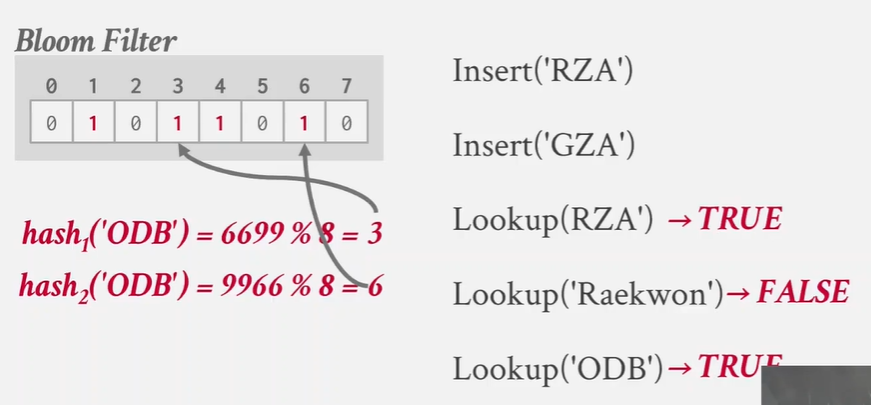
可能有误判断?
存在公式表明 -- 若要实现1%的误报率 所需的bloom filter大小应为指定尺寸 并配置相应数量的哈希函数
Extendable Hashing
更复杂的方案 -- Extendable Hashing(可扩展哈希)
类似于链式哈希 但能够分割桶避免无限长的桶链表
使得只需要在哈希表的一小部分进行增量操作 -- 不必重新哈希整个表
这一方法的核心思想在于 当我们需要在桶列表或桶哈希表中进行查找 来定位我们所需的桶链时 我们将扩展所需检视的位数 我们可以根据每个值 每种键类型或非键来调整这一点 也可以根据我们所查看的桶列表来进行调整
因此 可能存在 在我们的桶数组中 两个不同的位置会指向同一个桶列表 --但随着我们的深入这种情况可以扩展并分解
???
有一个槽数组 指向桶列表
有一个global identify --- 告诉我们需要查看多少位哈希值 以便确定我们在桶数组中进行查找的方式
每个桶列表有一个local identify 记录其局部位的大小 -- 即需要检查的位数
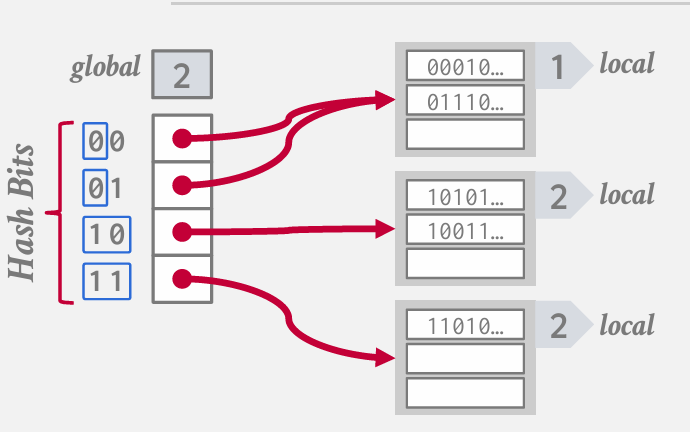
嗷嗷 第二个和第三个本来是一个桶 已经被分裂一次了
前两个槽位均指向同一个桶列表
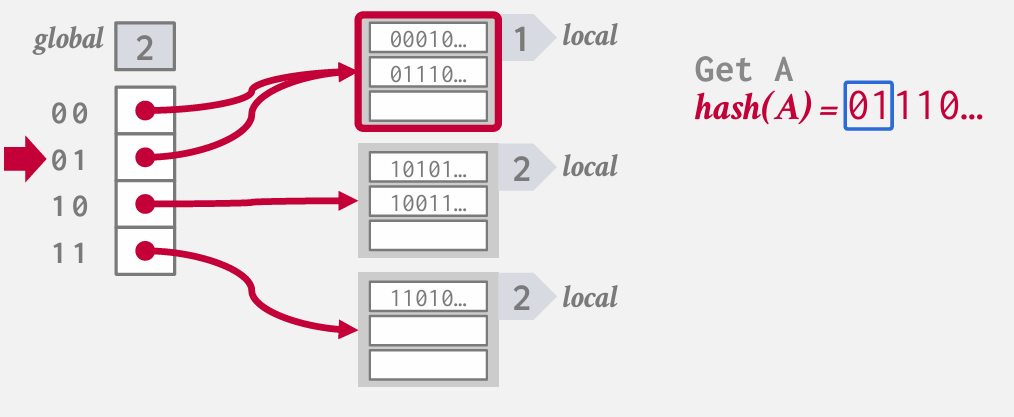
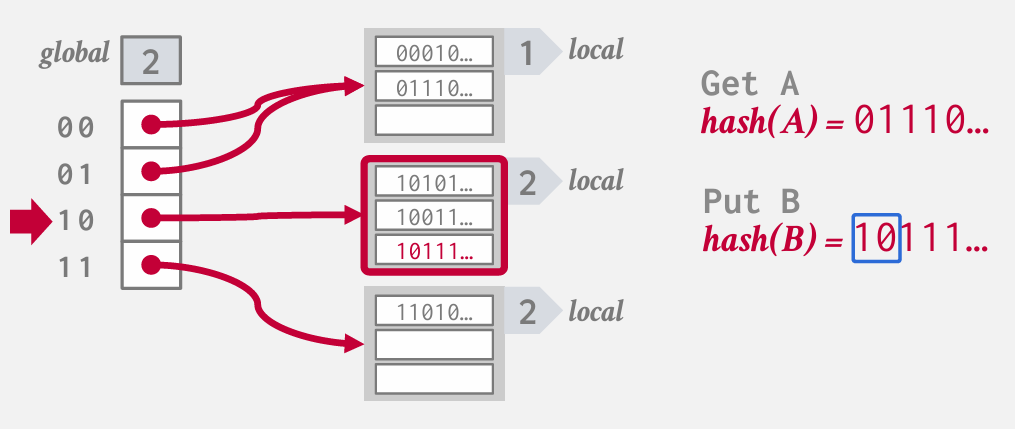
如果再插入C 但是第二个bucket已经满了
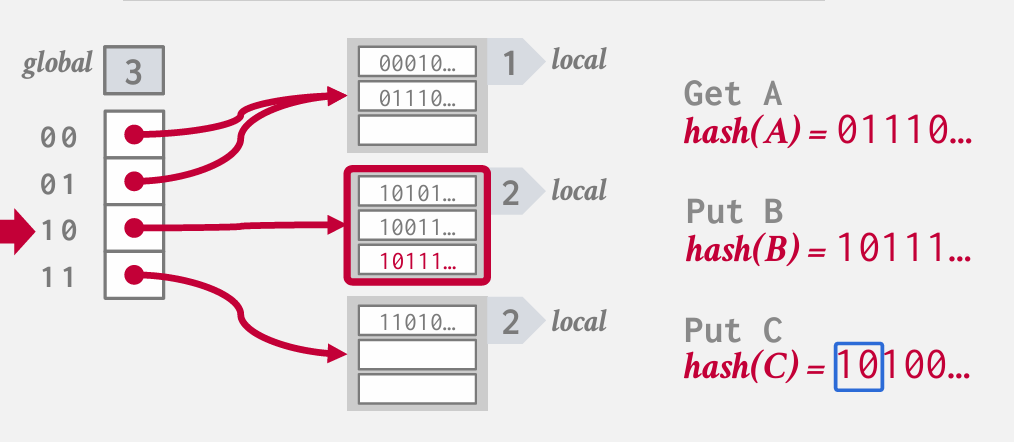
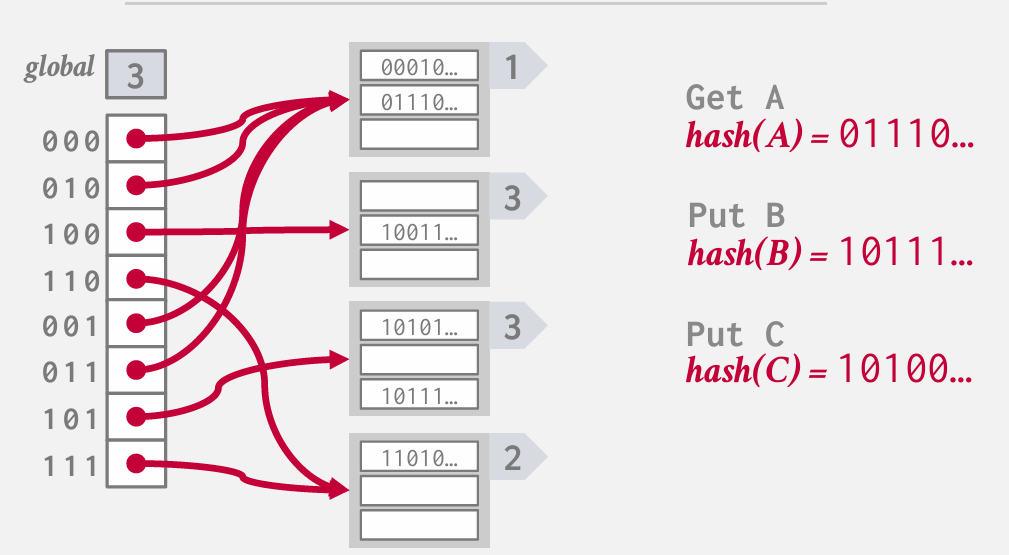
增加正在查看的位数 改为3 然后拆分
Linear Hashing
PostgreSQL BerkeleyDB
“线性哈希”(Linear Hashing)是数据库中的一种哈希表扩展策略。它的基本思路是跟踪一个split pointer(分割指针),指向下一个需要分裂的桶。当哈希表发生溢出时(即某个桶的数据过多),分裂操作会在此时触发,不管分裂指针当前指向哪里。
与传统的哈希表扩展方法不同,线性哈希不是一次性扩展整个哈希表,而是通过增量方式进行调整,即逐步扩展。这种方法的好处在于,它不会在调整大小时锁住整个表,而是允许在操作过程中进行小的增量调整,这样每次扩展的成本就比较低,而且可以由多个工作线程(workers)共同分担这个调整的成本。
摊销(amortized)调整大小的成本是指,扩展哈希表的成本不会一次性发生,而是随着多个操作逐步摊分,减轻每次操作的负担,从而避免了单次扩展时可能出现的高昂开销。
均摊 -- UNIT4 BAGS, QUERES, AND STACKS 这里面扩容的时候讲到过
我们维护多个哈希函数 这些函数将帮助我们确定在桶列表中的哪个位置进行查找
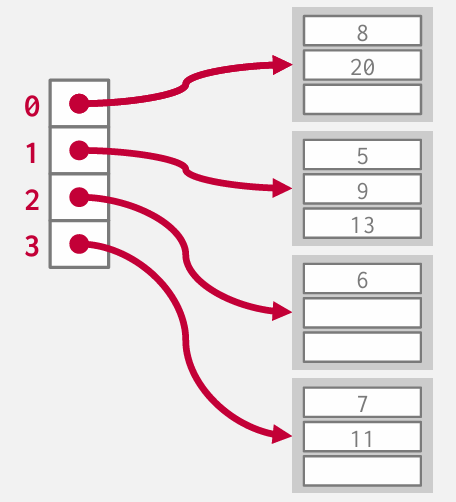
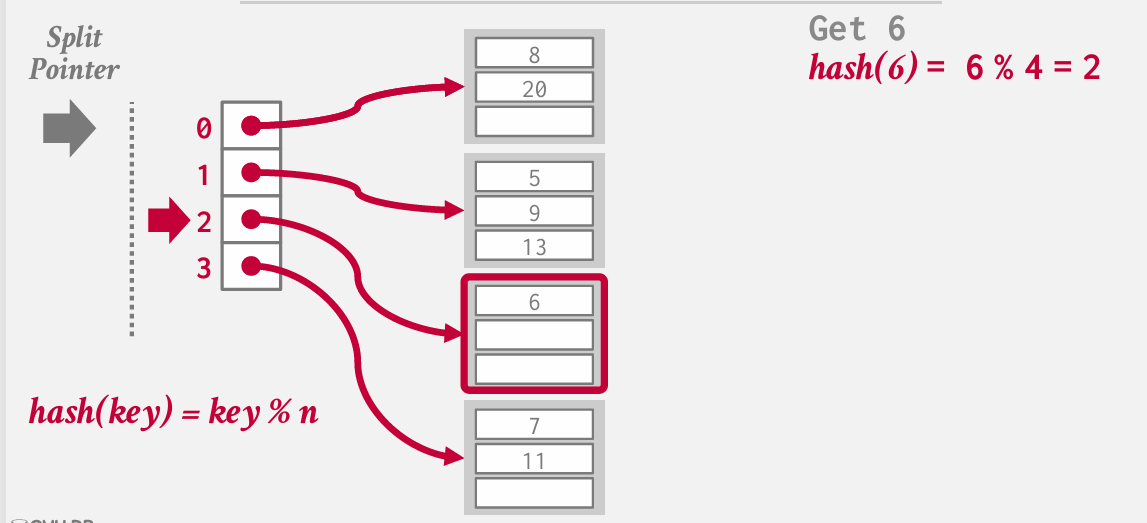
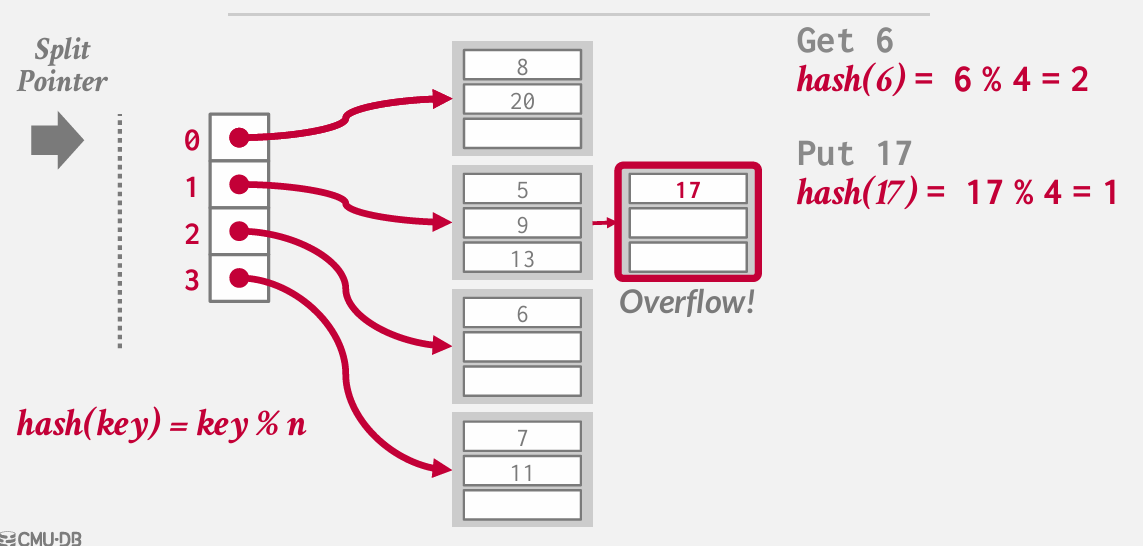
由于发生了溢出 我们要分裂 split pointer所指向的那个桶 尽管该桶并未发生溢出
现在我们要做的是查看这个桶列表中的所有条目 并基于2n对他们重新哈希
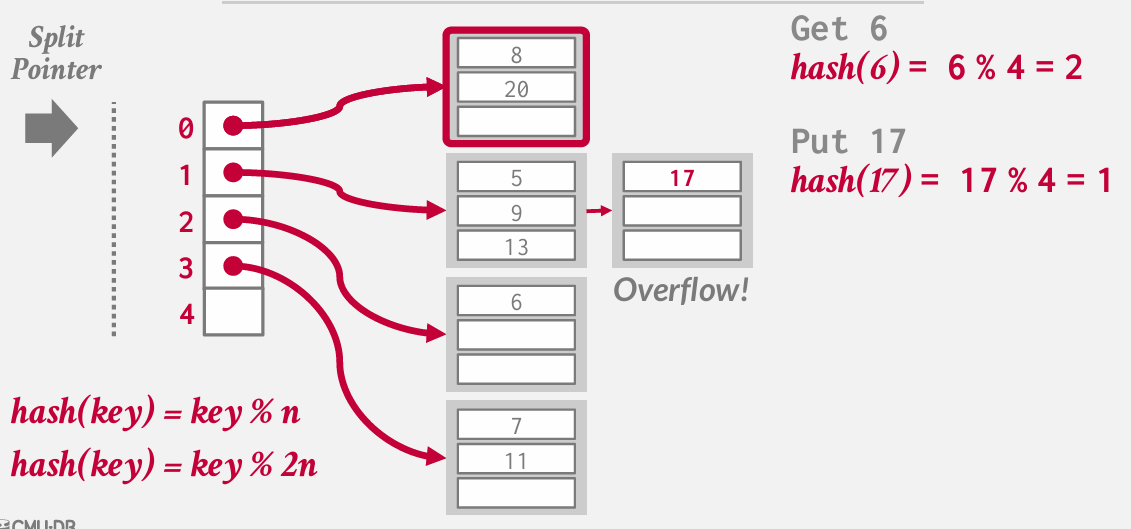
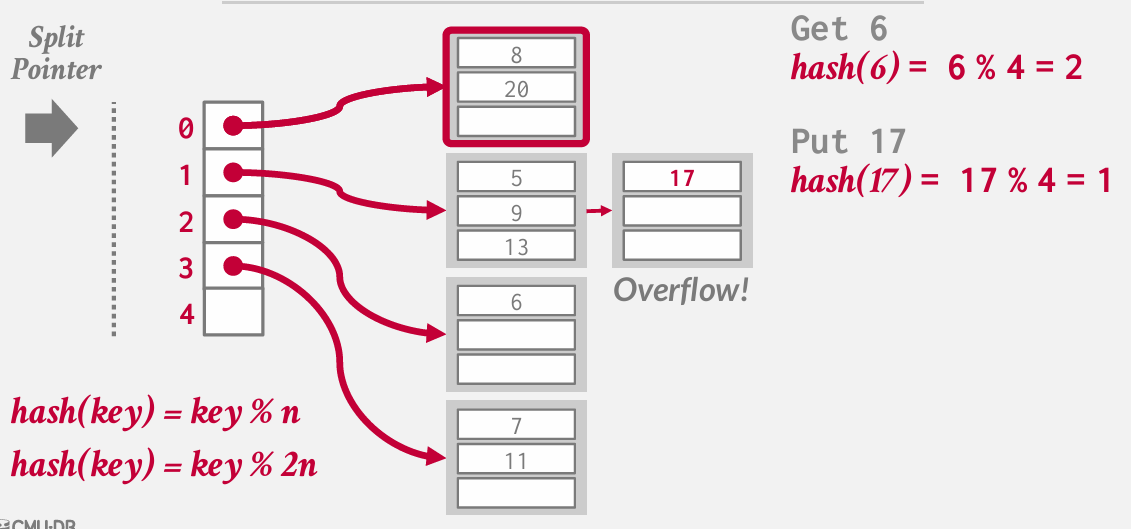
然后分割指针下移
如果现在要得到20 hash(20)=0 但我知道0位于split pointer的上方 知道对上面的部分进行了拆分
然后需要在对8模运算 找到正确的位置